Group Normalization详解
2023-12-22发布于深度学习 | 最后更新于2023-12-23 18:12:00
Group Normalization的内容以及Lazy与Sync机制
结合之前这些标准化方法,我们可以发现事实上都大同小异,唯一的区别就在于计算均值和方差这两个统计量的范围不一样。甚至如果自己发现了某种范围选取方法并且效果还可以,也是可以的。
回顾BN、LN与IN
此处先放上一张非常经典的示意图
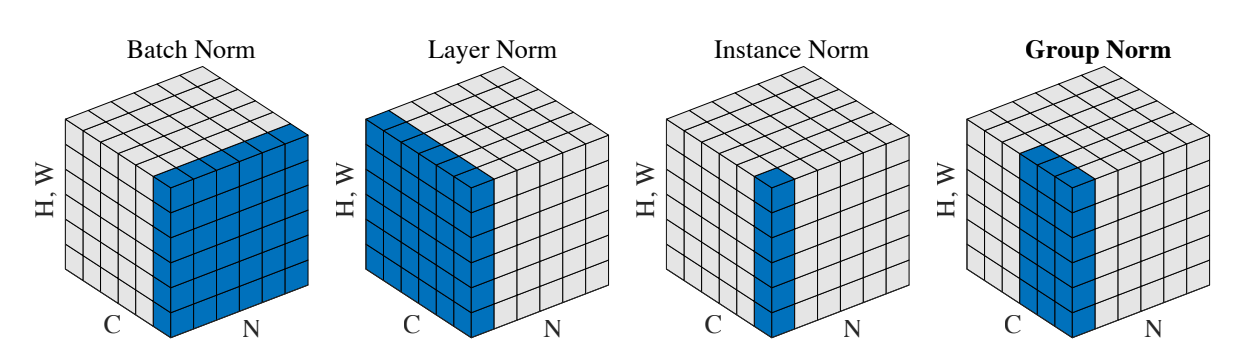
此示意图中,每个通道的大小为 \((H,W)\) ,即2d的情况,对示意图再做出几点理解:
- 每一竖条(Instance Norm中蓝色的)表示某一个样本的某一个通道,因此竖向以通道大小 \((H,W)\) 标注
- 左侧面每一片(Layer Norm中蓝色的)表示的是一个样本
- 右侧面每一片(Batch Norm中蓝色的)表示的是所有样本的同一通道
此时就可以很清楚的看到各标准化方法求统计量的范围了,此处借用之前看到过,个人认为非常清晰的三句话来解释:
- In Batch Normalization, we compute the mean and standard deviation across the various channels for the entire mini batch.
- In Layer Normalization, we compute the mean and standard deviation across the various channels for a single sample.
- In Instance Normalization, we compute the mean and standard deviation across each individual channel for a single sample.
- BN对整个mini batch的各个通道分别计算统计量,即统计量的组数(一组就是一个均值配上对应的方差)等于通道的个数
- LN计算各个样本中所有通道的统计量,即统计量的组数等于样本的个数
- IN对各个样本的各个通道分别计算统计量,即统计量的组数等于通道数乘样本数
Group Normalization
此时就可以很自然地看懂Group Normalization的示意图了,观察后可以发现其实LN和IN都是GN的一种特殊情况,除了这两个极端取值外,GN计算统计量的范围可以看成是LN的一种细分、IN的一种扩展。
先引出pytorch中GroupNorm定义时可以给入的参数
- 第一位置参数
num_groups,即要把一个样本的所有通道分成的组数 - 第二位置参数
num_channels,即一个样本的通道数
输入GroupNorm的数据大小为 \((N, C, *)\) , \(N\) 为样本数、 \(C\) 为通道数
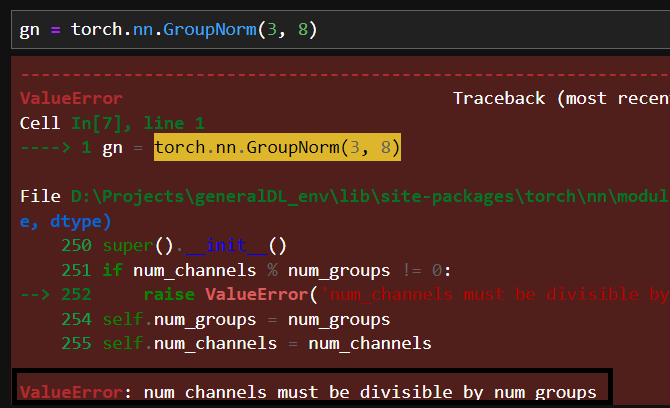
那么如果无法将num_channels个通道平均分为num_groups组怎么办?答案是不能这么做,num_channels必须能被num_groups整除,不然定义GN层时就会报错:
结合示意图可以发现:当分的组数等于通道数时,即每一组只有一个通道时,GN就相当于IN了;当分的组数取为1时,即把所有通道分到一组时,GN就相当于LN了。
这次验证我们自己写一个实现计算Group Normalization的函数,用以模仿GroupNorm的行为:
def myGroupNorm(data, num_groups, num_channels):
if num_channels % num_groups != 0:
raise ValueError("无法平均分")
group_size = num_channels//num_groups
N = data.shape[0]
C = data.shape[1]
# 获得一个通道的大小,即一个通道包含的数值个数
size_channel = data[0,0,].size
avg = []
var = []
for sample in range(N):
for channel in range(0, C, group_size):
avg.append(data[sample,channel:channel+group_size,].mean())
var.append(data[sample,channel:channel+group_size,].var())
avg = np.array(avg).repeat(size_channel * group_size).reshape(data.shape)
var = np.array(var).repeat(size_channel * group_size).reshape(data.shape)
return (data - avg) / np.sqrt(var)
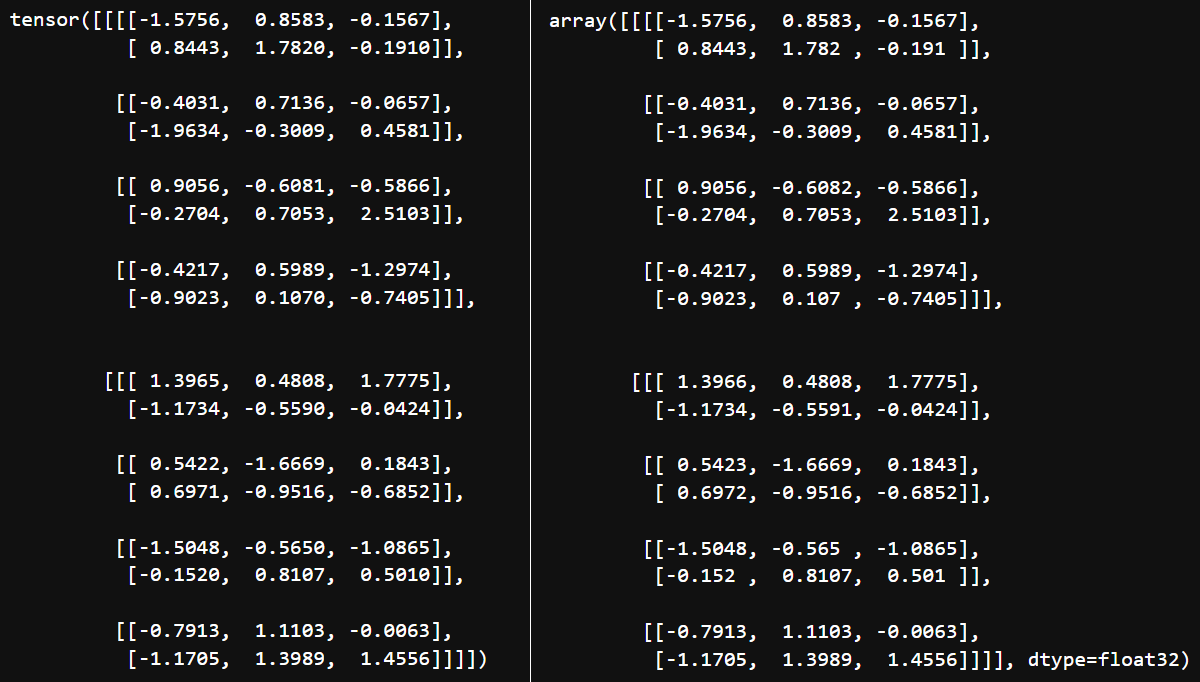
验证正确性如下:
N, C, H, W = (2, 4, 2, 3)
data = np.random.randn(N, C, H, W).astype(np.float32)
data_torch = torch.from_numpy(data)
gn = torch.nn.GroupNorm(2, C, affine=False)
gn(data_torch)
myGroupNorm(data, 2, C)
Lazy机制
在pytorch中,对于BN和IN都设计有Lazy机制,类名分别为
LazyBatchNorm1dLazyBatchNorm2dLazyBatchNorm3dLazyInstanceNorm1dLazyInstanceNorm2dLazyInstanceNorm3d
lazy顾名思义,在定义这些标准化层时无需指定num_features参数,会自动将输入向量的第1维(从0开始)的大小作为此参数的值,即通道数 \(C\) 。
Sync机制
在进行多卡并行训练时,一个batch中的各个样本会分布在各张GPU上,而各张GPU在并行计算时,并不能直接使用对方显存中的数据。也就是说,对于需要跨样本在整个batch中进行计算的Batch Normalization非常不利。在计算均值和方差时,若只着眼于当前GPU的数据,显然不太合适。因此,有人就想出了Sync的BN,即想办法让统计量能在GPU间同步。
我们先来看一下方差的计算:
其中 \(\displaystyle\sum_{i=1}^m{x_i}=m\mu\) :
也就是说,要计算全局的均值和方差,只需要进行 \(\displaystyle\sum_{i=1}^m{x_i^2}\) 和 \(\displaystyle\sum_{i=1}^m{x_i}\) 两个累加即可。
整个过程如下图所示:
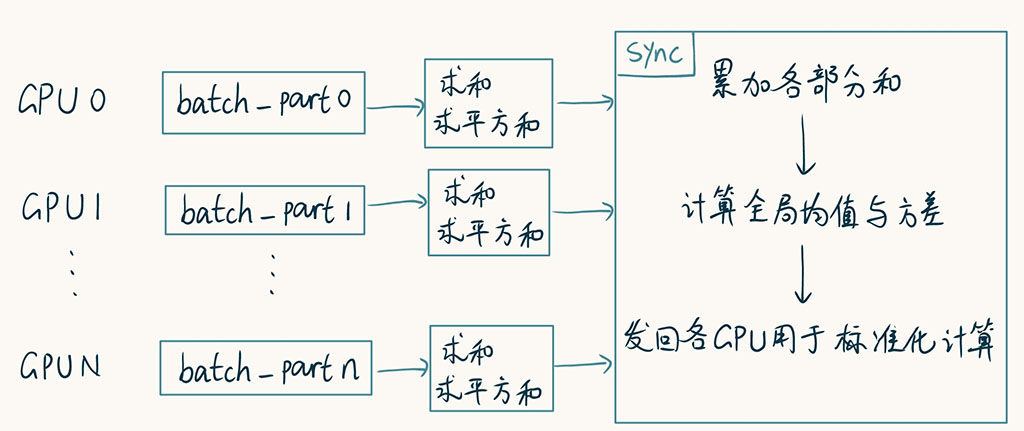
这就是torch.nn.SyncBatchNorm标准化层做的事情,需要配合DataParallel使用